Blog Zenvia
O melhor portal de Marketing e Vendas para a sua empresa
O melhor portal de Marketing e Vendas para a sua empresa
Confira como foram as etapas da implementação de uma estrutura de logs centralizada aqui na ZENVIA. Saiba mais!

Ter uma estrutura de logs centralizada, que pudesse ser utilizada por todas as equipes de operações era um sonho antigo. Tendo em vista, principalmente, que cada equipe possuía os seus próprios métodos de armazenamento e consulta de logs.
Confira como foram as etapas da implementação de uma estrutura de logs centralizada aqui na ZENVIA.
Inicialmente, os colaboradores mais experientes da empresa deram um overview das ferramentas e métodos já utilizados dentro da equipe SRE – Cloud, explicando o funcionamento da atual arquitetura e propondo algumas sugestões de melhorias sobre o cenário, para que atendessem todos os requisitos almejados.
Com isso, partimos em busca de uma tecnologia que atendesse da melhor maneira as nossas necessidades, com alguns desafios em relação à autenticação, autorização, integridade dos dados e à escalabilidade do ambiente.
Dentre algumas opções cogitadas, chegamos a um consenso dentro da equipe pela utilização do Amazon OpenSearch Service, anteriormente conhecido como Amazon Elasticsearch Service, uma vez que já estaria dentro do provedor de cloud utilizado pela ZENVIA e supria os requisitos demandados. Seria contratado com um serviço que, pensando pelo ponto de vista de infraestrutura, seria mais fácil administrar.
Primeiramente, realizamos o processo de provisionamento do serviço de forma manual, com o intuito de entender cada passo necessário para o funcionamento e identificar os pontos que precisaríamos do apoio de outras equipes.
Realizamos uma bateria de testes visando a escalabilidade do ambiente, no qual trocamos os tipos de máquinas, aumentamos quantidade de armazenamento e atualizamos versões, com o intuito de entender o comportamento da ferramenta diante dessas alterações e ter uma estimativa de tempo para manutenções futuras.
Sobre a etapa de autenticação, optamos pela utilização da integração com o Active Directory, uma vez que já fora utilizada em outras implementações e que, para esse caso, atendia as necessidades.
Nossa maior dificuldade foi em relação ao protocolo SAML, utilizado para a comunicação do Active Directory e o Serviço do OpenSearch, pois nunca tínhamos trabalhado com ele.
Com o apoio da equipe de Infraestrutura – Datacenter, em conjunto com a equipe SRE – Cloud e algumas semanas de trabalho, entendemos o funcionamento e conseguimos alcançar o objetivo, concluindo a etapa de autenticação de forma granular e utilizando os grupos do Active Directory para gerir as permissões.
Uma vez autenticado, partimos para a etapa de autorização, o que nos trouxe um novo desafio: como iríamos separar os dados dentro da aplicação sem perder o controle de acesso?
Existiam duas abordagens viáveis para solucionar o problema. Na primeira, iríamos despejar os dados em um ambiente global e dar as devidas permissões de acordo com a equipe correspondente.
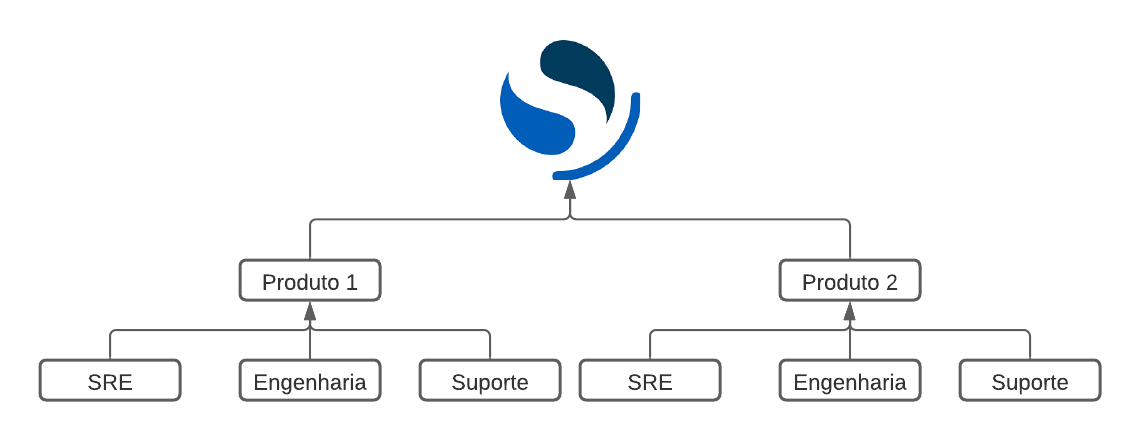
Na segunda abordagem, iríamos separar os dados por produtos e dentro de ambientes de trabalhos diferentes, dentro da ferramenta denominada “Tenants”, o que nos proporcionaria uma granularidade maior em relação aos acessos e que, do ponto de vista de administração, seria mais fácil mapear essas permissões com os grupos do Active Directory.
Exemplo da estrutura de permissionamento por produto.
Embora a autenticação utilizando um controlador de domínio nos proporcione maior segurança e controle, também era necessário garantir que a comunicação “Cliente-OpenSearch” possuísse a maior disponibilidade possível, pois é a responsável pelo envio propriamente dito dos logs para a ferramenta. T
endo em mente futuros possíveis problemas, sejam eles de comunicação com o controlador ou de indisponibilidade do mesmo, optamos pela autenticação básica para os serviços que enviam logs para o OpenSearch, uma vez que os usuários seriam criados diretamente na ferramenta, reduzindo possíveis problemas com os envios.
Com todos os testes realizados, a análise do comportamento do ambiente e consolidação de um estado aceitável relacionado aos requisitos solicitados, partimos para a criação do código IaC do OpenSearch.
Utilizamos o terraform como ferramenta de provisionamento via código, o que nos proporcionou um maior controle do estado do ambiente, bem como na sua recriação, com uma rápida convergência, tendo em vista que os códigos e o estado estão versionados no nosso repositório.
Com a etapa de implementação concluída e os dados sendo enviados para o OpenSearch, nos deparamos com um outro desafio: como gerenciar esses dados?
Esta foi a etapa que mais nos consumiu tempo, tendo em vista que era totalmente diferente do que já havia sido utilizada anteriormente e também é o que melhor diferencia o OpenSearch para o Elasticsearch.
A forma como o OpenSearch gerencia os dados é realizada através de políticas no formato json, onde é possível fazer com que os dados transitem entre os diferentes estados propostos, sendo eles:
Optamos por utilizar uma abordagem de classificação diária dos dados dentro da ferramenta, o que torna mais precisa as buscas.
Em relação aos tempos de retenção dos dados e aos tempos de armazenamento em cada estado, seguimos os padrões sugeridos pelo Comitê de Padronização em conjunto com o time de Segurança da Informação, no qual foram priorizadas questões de âmbito jurídico e legal.
E além dos controles configurados diretamente nas políticas, também realizamos backup dos dados em um repositório apartado do OpenSearch por um período maior de tempo, visando maior conformidade com normas e com solicitações de clientes.
A implementação desse ambiente foi um grande avanço tecnológico para a ZENVIA e para o desenvolvimento da equipe profissional envolvida.
Saímos da nossa zona de conforto, pela complexidade do tema e o valor agregado para a empresa. Um agradecimento especial ao apoio que recebemos de diversos colegas da equipe e também de outros times.
Agradecemos também à ZENVIA, que nos proporcionou essa experiência incrível e com imenso valor para o nosso desenvolvimento pessoal e profissional.
*Conteúdo produzido por Leonardo Jardim e Yuri Azeredo, ZENVIA